
- Введение
- Для чего нужен запрет индексации
- Запрещаем индексацию сайта
- Запрещаем индексацию страницы
- Популярные ошибки
- Делаем выводы
Введение
Сегодня трафик из поисковых систем для многих сайтов является основным источником посетителей. Для того, что бы Ваш ресурс появился в поиске, Yandex (Google, Rambler и т.д.) должен сначала найти его, а затем скачать к себе в базу. Этот процесс и называется индексацией.
Индексация проводится не один и не два раза. Робот посещает Ваш сайт на протяжении всей его «жизни» или до момента запрета. Именно о запрете сегодня и пойдет речь.
Запретить индексацию означает не дать участвовать в поиске всему сайту или определенному списку страниц.
Для чего нужен запрет индексации
Существует множество причин для полного и частичного запрета. Разберем по порядку.
-
Нежелание участвовать в поиске. Самая банальная причина. Вы просто не хотите, что бы сайт участвовал в результатах поиска.
-
Сайт находится в разработке. Робот индексирует сайт всегда, вне зависимости от того, находится он в разработке или уже закончен.
Поэтому, если работы проводятся не на локальном хостинге, то необходимо запретить поисковым системам индексировать сайт до тех пор, пока он не будет готов. Вот лишь ряд причин, почему необходимо скрывать от поисковика все, что еще не доделали.-
В процессе разработки размещается демо контент, уникальность которого крайне низка. Видеть такой материал поисковая система не должна.
-
Сайт разрабатывается без наполнения и окончательной структуры. Не нужно вводить в заблуждение поисковую систему, иначе ресурс будет признан не интересным для пользователей еще до того, как его наполнят.
-
Во время технических работ появляется множество дублей страниц. Нельзя допустить попадания их в индекс.
-
Ряд других технических причин.
-
-
Информация не для поиска. На любом сайте существуют страницы и разделы, которые не должны участвовать в поиске. К ним относится система управления сайта, результаты вычислений, дубликаты URL, неуникальный контент, не индексируемые документы и т.д.
- Страницы в разработке. Если сайт уже давно присутствует в поиске, но часть страниц находится на стадии редактирования, то их необходимо скрыть от индексирующего робота.
Запрещаем индексацию сайта
Для того, что бы полностью запретить индексацию сайта, необходимо, что бы при обращении к нему робот получал запрет в виде инструкции. Сделать это можно двумя способами.
При помощи robots.txt
Это наиболее распространенный и менее трудозатратный способ. Для того, что бы полностью закрыть сайт необходимо прописать в файле robots.txt простую инструкцию:
User-agent: *
Disallow: /
Таким образом вы запрещаете индексацию для любой поисковой системы. Но есть возможность запрета и для конкретного поисковика, к примеру, Яндекса.
User-agent: Yandex
Disallow: /
Подробнее о синтаксисе и работе с файлом robots.txt — https://dh-agency.ru/category/vnutrennyaya-optimizaciya/robots-txt/
При помощи тэгов
Так же, существует способ закрыть свой сайт при помощи специального тэга. Он будет «говорить» индексирующему роботу при обращении к странице, что ее загружать не надо.
<meta name=»robots» content=»noindex»>
Данный тэг необходимо разместить на каждой странице Вашего сайта.
Параметр поля «name» зависит от робота, к которому Вы обращаетесь. К примеру, если речь идет о роботе Google, то данный тэг будет выглядеть следующим образом:
<meta name=»googlebot» content=»noindex»>
О том, какие значения может принимать параметр «content», читайте ниже.
Запрещаем индексацию страницы
Запрет индексации одной единственной страницы отличается от запрета всего сайта только наличием дополнительной инструкции и URL адреса. Причем исключить из индекса можно не только конкретный адрес, но и маску. Однако возможность эта имеется только при работе с файлом robots.txt.
При помощи robots.txt
Для запрета конкретной страницы (спектра страниц по маске) используется инструкция «Disallow:». Синтаксис крайне простой:
Disallow: /wp-admin (исключаем всю папку wp-admin)
Disallow: /wp-content/plugins (исключаем папку plugins, которая находится в wp-content)
Disallow: /img/images.jpg (исключаем изображение images.jpg, которое находится в папке img)
Disallow: /dogovor.pdf (исключаем файл /dogovor.pdf)
Disallow: */trackback (исключаем папку trackback в любой папке первого уровня)
Disallow: /*my (исключаем любую папку заканчивающуюся на my)
Все достаточно просто, не правда ли? Но это позволяет избавиться от множества проблем во время продвижения сайта. Актуализируйте robots.txt каждый месяц в зависимости от апдейтов Яндекса и Гугла.
При помощи тэгов
Исключение возможно и при помощи тэга <meta name=»robots» content=»noindex»>. Для этого необходимо просто вписать его в код конкретной страницы, которую Вы хотите закрыть от поисковиков.
Данный тэг размещается в <head> сайта, наряду с другими meta тэгами.
Стоит отметить, что значение параметра «content» может быть не только «noindex». Рассмотрим все возможные варианты.
| noindex | Самый распространенный параметр. Запрещает индексацию. |
| index | Обратный предыдущему параметр. Разрешает индексацию. Обычно не применяется, так как поисковая система по умолчанию индексирует все. |
| follow | Разрешает следовать по ссылкам, которые расположены на странице. Так же редко применяется, так как и без данного тэга краулер будет переходить по ссылкам. |
| nofollow | Запрещает переходить по ссылкам. |
Популярные ошибки
Существует множество мелких и досадных ошибок, из-за которых можно потерять кучу времени и сил.
- Запрет индексации в CMS.
У ряда CMS (к примеру, у WordPress) и шаблонов по умолчанию стоит галочка — «не индексировать сайт». Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания.

К сожалению, не все вспоминают о ней по окончании работ.
- Синтаксические ошибки.
Синтаксические ошибки в файле robots.txt и тэгах часто приводят к совершенно непредсказуемым последствиям. Вам повезет, если после такого недочета в индекс просто попадут лишние страницы. Очень часто весь сайт закрывается, что в последствии приводит к полной потере органического трафика.
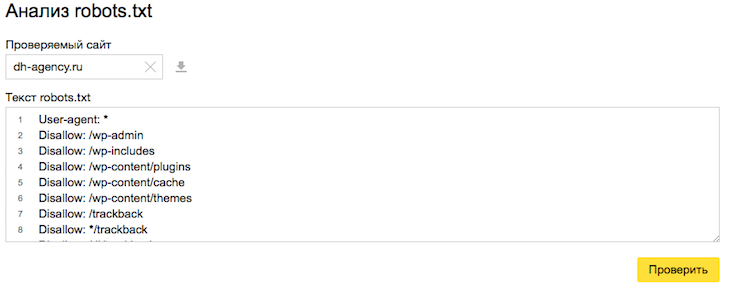
Для того, что бы избежать подобных ошибок, необходимо несколько раз перепроверить изменения, а так же воспользоваться инструментами валидации синтаксиса. К примеру, стандартным сервисом Яндекса.
Яндекс Вебмастер -> Инструменты -> Анализ robots.txt
- Неверное использование масок.
Неверное использование масок может привести к исключению целого дерева страниц, документов и разделов. Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.
Делаем выводы
Сам по себе технический процесс исключения достаточно прост. Вся работа заключается в выяснении того, что необходимо исключить и на какой срок.
Если Вы не уверены в правильности своих действий, лучше оставьте в индексе все. Поисковая система сама выберет то, что для нее важно.
Но мы настоятельно рекомендуем обратиться за консультацией при малейших сомнениях.