
- Зачем robots.txt в SEO?
- Создаем robots самостоятельно
- Синтаксис robots.txt
- Обращение к индексирующему роботу
- Запрет индексации Disallow
- Разрешение индексации Allow
- Директива host robots.txt
- Sitemap.xml в robots.txt
- Использование директивы Clean-param
- Использование директивы Crawl-delay
- Комментарии в robots.txt
- Маски в robots.txt
- Как правильно настроить robots.txt?
- Проверяем свой robots.txt
Robots — это обыкновенный текстовой файл (.txt), который располагается в корне сайта наряду c index.php и другими системными файлами. Его можно загрузить через FTP или создать в файловом менеджере у хост-провайдера. Создается данный файл как обыкновенный текстовой документ с самым простым форматом — TXT. Далее файлу присваивается имя ROBOTS. Выглядит это следующим образом:

(robots.txt в корневой папке WordPress)
После создание самого файла нужно убедиться, что он доступен по ссылке ваш домен/robots.txt. Именно по этому адресу поисковая система будет искать данный файл.
В большинстве систем управления сайтами роботс присутствует по умолчанию, однако зачастую он настроен не полностью или совсем пуст. В любом случае, нам придется его править, так как для 95% проектов шаблонный вариант не подойдет.
Зачем robots.txt в SEO?
Первое, на что обращает внимание оптимизатор при анализе/начале продвижения сайта — это роботс. Именно в нем располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главной зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса. Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен/robots.txt. Не допускается наличие вложений, к примеру ваш домен/page/robots.txt.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.txt. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots начинается с директивы User-agent:, которая указывает для какой поисковой системы или для какого робота приведены инструкции ниже. Пример использования:
User-agent: Yandex User-agent: YandexBot User-agent: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота. Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Yandex
| Название | Описание | Предназначение |
| YandexBot | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| YandexDirect | Работ контекстной рекламы | Оценивает сайты с точки зрения расположения на них контекстных объявлений. |
| YandexDirectDyn | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| YandexMedia | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| YandexImages | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл robots особым образом. Подробнее о нем можно прочесть у Яндекса. |
| YandexBlogs | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| YandexNews | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| YandexPagechecker | Робот микроразметки | Данный робот отвечает за индексацию и распознание микроразметки сайта. |
| YandexMetrika | Робот Яндекс Метрики | Тут все и так ясно. |
| YandexMarket | Робот Яндекс Маркета | Отвечает за индексацию товаров, описаний, цен и всего того, что относится к Маркету. |
| YandexCalendar | Робот Календаря | Отвечает за индексацию всего, что связано с Яндекс Календарем. |
Роботы Google
| Название | Описание | Предназначение |
| Googlebot | (Googlebot) Основной индексирующий роботом Google. | Индексирует основной текстовой контент страницы. Отвечает за основную органическую выдачу. Запрет приведет к полному отсутствия сайта в поиске. |
| Googlebot-News | (Googlebot News) Новостной робот. | Отвечает за индексирование сайта в новостях. Запрет приведет к отсутствию сайта в разделе «Новости» |
| Googlebot-Image | (Googlebot Images) Индексация изображений. | Отвечает за графический контент сайта. Запрет приведет к отсутствию сайта в выдаче в разделе «Изображения» |
| Googlebot-Video | (Googlebot Video) Индексация видео файлов. | Отвечает за видео контент. Запрет приведет к отсутствию сайта в выдаче в разделе «Видео» |
| Googlebot | (Google Smartphone) Робот для смартфонов. | Основной индексирующий робот для мобильных устройств. |
| Mediapartners-Google | (Google Mobile AdSense) Робот мобильной контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных мобильных объявлений. |
| Mediapartners-Google | (Google AdSense) Робот контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных объявлений. |
| AdsBot-Google | (Google AdsBot) Проверка качества страницы. | Отвечает за качество целевой страницы — контент, скорость загрузки, навигация и т.д. |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений | Сканирование для мобильных приложений. Оценивает качество так же, как и предыдущий робот AdsBot |
Обычно robots.txt настраивается для всех роботов Яндекса и Гугла сразу. Очень редко приходится делать отдельные настройки для каждого конкретного краулера. Однако это возможно.
Другие поисковые системы, такие как Bing, Mail, Rambler, так же индексируют сайт и обращаются к robots.txt, однако мы не будем заострять на них внимание. Про менее популярные поисковики мы напишем отдельную статью.
Запрет индексации Disallow
Без сомнения самая популярная директива. Именно при помощи disallow страницы исключаются из индекса. Disallow — буквально означает запрет на индексацию страницы, раздела, файла или группы страниц (при помощи маски). Рассмотрим пример:
Disallow: /wp-admin Disallow: /wp-content/plugins Disallow: /img/images.jpg Disallow: /dogovor.pdf Disallow: */trackback Disallow: /*my
Строка 1 — запрет на индексацию всего раздела wp-admin
Строка 2 — запрет на индексацию подраздела plugins
Строка 3 — запрет на индексацию изображения в папке img
Строка 4 — запрет индексации документа
Строка 5 — запрет на индексацию trackback в любой папке на 1 уровень
Строка 6 — запрет на индексацию не только /my, но и /folder/my или /foldermy
Данная директива поддерживает маски, о которых мы подробнее напишем ниже.
После Disallow в обязательном порядке ставится пробел, а вот в конце строки пробела быть не должно. Так же, допускается написание комментария в одной строке с директивой через пробел после символа «#», однако это не рекомендуется.
Указание нескольких каталогов в одной инструкции не допускается!
Разрешение индексации Allow
Обратная Disallow директива Allow разрешает индексацию конкретного раздела. Заходить на Ваш сайт или нет решает поисковая система, но данная директива ей это позволяет. Обычно Allow не применяется, так как поисковая система старается индексировать весь материал сайта, который может быть полезен человеку.
Пример использования Allow
Allow: /img/ Allow: /dogovor.pdf Allow: /trackback.html Allow: /*my
Строка 1 — разрешает индексацию всего каталога /img/
Строка 2 — разрешает индексацию документа
Строка 3 — разрешает индексацию страницы
Строка 4 — разрешает индексацию по маске *my
Данная директива поддерживает и подчиняется всем тем же правилам, которые справедливы для Disallow.
Директива host robots.txt
Данная директива позволяет обозначить главное зеркало сайта. Обычно, зеркала отличаются наличием или отсутствием www. Данная директива применяется в каждом robots и учитывается большинством поисковых систем.
Пример использования:
Host: dh-agency.ru
Если вы не пропишите главное зеркало сайта через host, Яндекс сообщит Вам об этом в Вебмастере.

Не знаете главное зеркало сайта? Определить довольно просто. Вбейте в поиск Яндекса адрес своего сайта и посмотрите выдачу. Если перед доменом присутствует www, то значит главное зеркало у вас с www.
Если же сайт еще не участвует в поиске, то в Яндекс Вебмастере в разделе «Переезд сайта» Вы можете задать главное зеркало самостоятельно.
Sitemap.xml в robots.txt
Данную директиву желательно иметь в каждом robots.txt, так как ее используют yandex, google, а так же все основные поисковые системы. Директива представляет из себя ссылку на файл sitemap.xml в котором содержатся все страницы, которые предназначены для индексирования. Так же в sitemap указываются приоритеты и даты изменения.
Пример использования:
Sitemap: http://dh-agency.ru/sitemap.xml
О том, как правильно создавать sitemap.xml мы напишем чуть позже.
Использование директивы Clean-param
Очень полезная, но мало кем применяющаяся директива. Clean-param позволяет описать динамические части URL, которые не меняют содержимое страницы. Такими динамическими частями могут быть:
- Идентификаторы сессий;
- Идентификаторы пользователей;
- Различные индивидуальные префиксы не меняющие содержимое;
- Другие подобные элементы.
Clean-param позволяет поисковым системам не загружать один и тот же материал многократно, что делает обход сайта роботом намного эффективнее.
Объясним на примере. Предположим, что для определения с какого сайта перешел пользователь мы взяли параметр site. Данный параметр будет меняться в зависимости от ресурса, но контент страницы будет одним и тем же.
http://dh-agency.ru/folder/page.php?site=x&r_id=985 http://dh-agency.ru/folder/page.php?site=y&r_id=985 http://dh-agency.ru/folder/page.php?site=z&r_id=985
Все три ссылки разные, но они отдают одинаковое содержимое страницы, поэтому индексирующий робот загрузит 3 копии контента. Что бы этого избежать пропишем следующие директивы:
User-agent: Yandex Disallow: Clean-param: site /folder/page.php
В данном случае робот Яндекса либо сведет все страницы к одному варианту, либо проиндексирует ссылку без параметра. Если такая конечно есть.
Использование директивы Crawl-delay
Довольно редко используемая директива, которая позволяет задать роботу минимальный промежуток между загружаемыми страницами. Crawl-delay применяется, когда сервер нагружен и не успевает отвечать на запросы. Промежуток задается в секундах. К примеру:
User-agent: Yandex Crawl-delay: 3
В данном случае таймаут будет 3 секунды. Кстати, стоит отметить, что Яндекс поддерживает и не целые значения в данной директиве. К примеру, 0.4 секунды.
Комментарии в robots.txt
Хороший robots.txt всегда пишется с комментариями. Это упростит работу Вам и поможет будущим специалистам.
Что бы написать комментарий, который будет игнорировать робот поисковой системы, необходимо поставить символ «#». К примеру:
#мой роботс Disallow: /wp-admin Disallow: /wp-content/plugins
Так же возможно, но не желательно, использовать комментарий в одной строке с инструкцией.
Disallow: /wp-admin #исключаем wp admin Disallow: /wp-content/plugins
На данный момент никаких технических запретов по написанию комментария в одной строке с инструкцией нету, однако это считается плохим тоном.
Маски в robots.txt
Применение масок в robots.txt не только упрощает работу, но зачастую просто необходимо. Напомним, маска — это условная запись, которая содержит в себе имена нескольких файлов или папок. Маски применяются для групповых операций с файлами/папками. Предположим, что у нас есть список файлов в папке /documents/
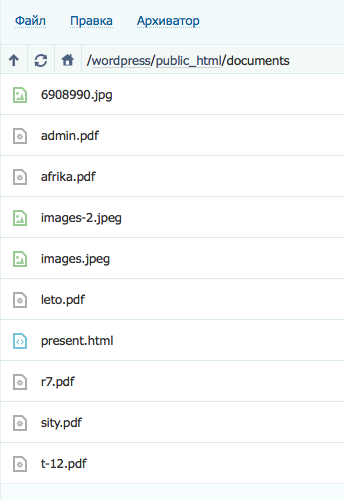
Среди этих файлов есть презентации в формате pdf. Мы не хотим, что бы их сканировал робот, поэтому исключаем из поиска.
Мы можем перечислять все файлы формата .pdf «в ручную»
Disallow: /documents/admin.pdf Disallow: /documents/r7.pdf Disallow: /documents/leto.pdf Disallow: /documents/sity.pdf Disallow: /documents/afrika.pdf Disallow: /documents/t-12.pdf
А можем сделать простую маску *.pdf и скрыть все файлы в одной инструкции.
Disallow: /documents/*.pdf
Удобно, не правда ли?
Маски создаются при помощи спецсимвола «*». Он обозначает любую последовательность символов, в том числе и пробел. Примеры использования:
Disallow: *.pdf Disallow: admin*.pdf Disallow: a*m.pdf Disallow: /img/*.* Disallow: img.* Disallow: &=*
Стоит отметить, что по умолчанию спецсимвол «*» добавляется в конце каждой инструкции, которую Вы прописываете. То есть,
Disallow: /wp-admin # равносильно инструкции ниже Disallow: /wp-admin*
То есть, мы исключаем все, что находится в папке /wp-admin, а так же /wp-admin.html, /wp-admin.pdf и т.д. Для того, что бы этого не происходило необходимо в конце инструкции поставить другой спецсимвол — «$».
Disallow: /wp-admin$ #
В таком случае, мы уже не запрещаем файлы /wp-admin.html, /wp-admin.pdf и т.д
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. Использование данной директивы мы описали выше. Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно.
Использование Crawl-delay зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Проверяем свой robots.txt
После настройки файла его необходимо проверить. Сделать это возможно через Ваш Вебмастер в разделе «Инструменты» -> «Анализ robots.txt»
Но нужно понимать, что данный онлайн инструмент сможет лишь найти синтаксическую ошибку. Он никак не убережет Вас от лишней исключенной страницы, а так же от мусора в выдаче.
Было полезно почитать. Спасибо!
Сделайте возможность подписки, рассылки новых статей
Егор, спасибо!
В ближайшее время реализуем возможность подписки.
Только инфа и никакой воды, отлично, спасибо!
Спасибо
Здравствуйте!
Посоветуйте, пожалуйста, решение вот в такой ситуации:
сайт предприятия сделан в конструкторе, куплен домен в зоне .рф. В поисковой выдаче встречаются страницы обоих доменов — «родного» и покупного (соотв., web143746.redham.ru и севэнергоизоляция.рф/).
Думаю, что на это влияет тот факт, что в файле robots.txt в директиве Host прописана команда xn--b1aceblfbxnmcti5fxevbc.xn--p1ai, а не севэнергоизоляция.рф.
Считаю, нужно указать директиве Host команду севэнергоизоляция.рф ИЛИ вовсе удалить директиву Host.
Что будет лучшим решением?
Хочется узнать Ваше мнение.
С уважением,
Сергей.
Добрый день!
В host кириллический домен должен быть указан в Punycode. То есть, прописать его кириллицей нельзя.
Полностью удалять эту директиву тоже не нужно.
В данной ситуации лучше всего было бы сделать 301 редирект со старого домена на новый «.рф». (при этом все пользователи всегда будут переадресовываться на домен «.рф»).
Или ожидать пока зеркала склеятся и главным будет «.рф».
Мы нашли для Вас соответствующий пост у Яндекса — yandex.ru/blog/platon/2073 в нем более подробно рассказывается про разноименные домены
Признателен Вам, Антон, за достаточный ответ и его оперативность!
А также благодарю за ваш сайт!
Всего доброго!
Спасибо! Всегда рады помочь, обращайтесь
Доброе утро, Алексей!
Позвольте ещё задать пару вопросов?
1) Отредактировал файл robots, написал в поддержку конструктора, чб они заменили содержимое (пользователям данная функция не доступна((( ). Сделали. Но на предмет корректности поддержка не консультирует. При проверке в Янд.Вэбм. ошибок найдено не было. И всё же хочу заручиться словом живого человека-специалиста: всё ли в файле так (ибо проверка на пинг вот здесь — pr-cy.ru/monitoring/ — выдаёт «Код ошибки клиента. Сервер понял запрос, но не нашёл соответствующего ресурса по указанному URI.»)?
Если не трудно, будьте добры, гляньте: севэнергоизоляция.рф/robots.txt.
2) «Сделать 301 редирект» — это в Янд.Вэбмрстере делается или в настройках ПУ сайтом?
Благодарю Вас!!!
Здравствуйте, Сергей!
С host в robots.txt у Вас все в порядке. Я проверил домен в Вебмастере — код овтета 200 (все хорошо)
301 редирект проставляется в файле .htaccess, который расположен в корневой папке сайта. В поддержке конструктора должны знать, как это делается.
Но мы бы Вам посоветовали перейти от конструктора к сайту на собственном хостинге. Обычно, конструкторы позволяют делать далеко не все, что необходимо для оптимизации. К примеру, скорость загрузки Вашего сайта довольно низкая — gtmetrix.com/reports/xn--b1aceblfbxnmcti5fxevbc.xn--p1ai/pno4lUIG. Вряд ли это получится исправить на конструкторе.
Обратился в техподдержку.
Ответили: «Перейдите в настройки и далее настройки SEO. Там вы можете сделать 301 редирект.»
Сделано.
На собственный хостинг, конечно, хорошо. Но фирма уже оплатила тариф конструктора на год… Не станет, думаю, руководство терять вложенные средства (хотя, иначе — из-за медл.скорости теряем потенциальных заказчиков услуг через сайт…).
И кстати, в таких случаях переноса сайтов техподдержка должна предоставить весь сайт «мне в руки» или же сейчас хостинг-сервисы сами могут сделать перенос с любой площадки? Не в курсе?
Всего доброго Вам!!!
После всех проведенных действий нужно дождаться пока «.рф» станет основным доменом. На это может уйти 3-4 обновления поисковой базы.
Что касается переноса, то с конструкторов сайты очень проблематично переносить. У некоторых фирм это просто невозможно. Сложность в том, что CMS у конструктора обычно уникальная и Вам ее не передадут. Вы сможете забрать базу данных с контентом и в некоторых случаях дизайн.
«…3-4 обновления поисковой базы…» — это сколько может быть в днях (неделях)?
По вопросу возможности переноса, значит, нужно обратиться в поддержку… Интересен ли будет ответ или уж не отписываться здесь?
Благодарю Вас, Алексей!
Всего доброго!!!
Сергей, Вы можете написать ответ в форму связи (находится в подвале сайта). Туда же можете задавать новые вопросы, если появятся.
У нас есть группа в ВК (пока только начала развиваться) — https://vk.com/dh_agency, там тоже можно задать вопрос в разделе «Вопросы»
Если говорить о сроках, то 3-4 обновления поисковой базы это, обычно, 2-4 недели. Все будет зависеть от Яндекса.
Да, Алексей, извините, что из-за меня много лишнего теперь в комментариях, впору чистить.
Благодарю Вас и желаю успеха!
С уважением.
Здравствуйте.
Подскажите пожалуйста. У меня на сайте 4 основных страницы. Страницы: главная, скачать, тарифы и поддержка.
На странице Поддержки форма обратной связи + секция FAQ.
Нужно ли ее скрывать от поисковиков?
Страница Тарифов — там описание тарифов моего продукта + кнопки купить. Нужно ли ее скрывать?
Вся важная инфа о продукте на Главной.
Заранее спасибо за ответ.
Добрый вечер, Денис!
Если на странице «Поддержка» есть FAQ, где размещена уникальная информация, то скрывать от поисковиков его не нужно. Вопросы охотно индексируются поисковиками. Но, даже если бы вопросов не было, а была просто форма обратной связи с небольшим описанием, его бы все равно не нужно было скрывать. Так как форма связи — это коммерческий сигнал для поисковика.
Страницу тарифов так же не надо исключать из поиска. Описание будет индексироваться, а кнопка «Купить» улучшит коммерческие факторы сайта.
Если Вы напишите нам на почту info@dh-agency.ru и пришлете ссылку на сайт, то мы сможем ответить более подробно.
Ссылку на сайт отправил на почту 🙂
Подскажите пожалуйста. Нужно ли закрывать от индексирования ссылку на скачивание самого приложения? Вставил rel=»nofollow», но не уверен стоит ли. Просто приложение весит, к примеру, 20 Mb — будет ли робот его скачивать?.. — т.к. на обход сайта у робота время ограничено и это скачивание может занять время… C другой стороны, открыв доступ роботу, ссылка на скачивание приложения возможно может появиться в сниппете в поисковике…
Здравствуйте!
Если речь идет о странице скачивания — закрывать точно не стоит.
Если речь идет о самом приложении, то его закрывать тоже не нужно. Сканирующий робот довольно «умный» и проблем со ссылкой не будет.
Реально информация помогла. яндекс донимал то своим роботсом, то сайтмапом. Все доступно описано.
Спасибо админу.
Добрый день. Посмотрел роботс на вашем сайте и там в нем запрещены фиды для индексации. Подскажите почему вы так сделали? Это же не дубли станиц. Тот же яндекс при слияние сайта с Дзеном просит открыть ему фиды. Так как быть?
Яндекс отказался от директивы Host. Можно убирать. 🙂
Вот в этой статье {ссылка} автор утверждает о том, что если открыть uploads для всех ботов, то в индексе появляются загруженные PDF и прочие текстовые файлы. А в яндекс вебмастере, в отчете «Исключенные страницы» появляются сообщения об ошибке при индексировании картинок, мол содержимое не поддерживается. Вот и не знаю кому верить… Помогите разобраться в конце-то концов